
Introduction
Recently, Andrej Karpathy made his autoresearch workflow public: https://github.com/karpathy/autoresearch. The idea is to autonomously improve a model’s training process based on experiment results. Using Claude Code, you run this loop for hours or days and end up with a better model. The whole flow is described in the program.md file as a skill: https://github.com/karpathy/autoresearch/blob/master/program.md
I’m not training any LLMs for work or even as a hobby, but I do a lot of coding, now mostly with Claude Code. To generate high-quality code that consistently follows conventions and standards, I use multiple skills, memory files, sub-agents, hooks, etc., let’s call it an agentic harness.
However, I evaluate this harness rather naively, not based on experiments or metrics – let’s say, not scientifically. The usual approach has been: test best practices that feel useful -> if they work -> incorporate them into the workflow. Or, if issues are caught during human review -> fix the workflow.
But I think I can borrow ideas from Karpathy’s autoresearch and adapt them to improve my agentic coding harness based on deterministic experiments.
Let’s design a coding skill auto-improvement loop.
Solution
Assume we have a skill that implements a common workflow for daily coding:
take a request/task -> explore -> plan -> execute -> review.
For simplicity, we exclude any interactive steps that require user input. Optimizing those would require a more complex experimental framework.
The core of the autoresearch loop is an experiment that evaluates a new version (generation) based on its results. For that, we need deterministic experiments and stable metrics. This means outputs and measurements must be comparable across runs and generations.
What is the goal of this skill?
To determine the right steps and provide the right context to the coding agent so that the resulting code is predictable, follows standards, and passes human review.
But code quality is not the only concern. We also want:
- High autonomy (minimal escalation to humans)
- Ability to run many tasks in parallel
- Minimal token usage
- Low execution time
Evaluation Framework
We define a collection of test cases for the skill:
Request/Task -> Reference Code
Metrics:
- Token usage (end-to-end and per step), or even cost in real money – also helps optimize model selection per step
- Execution time (end-to-end and per step)
- Number of tool calls (to reduce unnecessary permissions and overhead)
- Number of errors, self-corrections, or full aborts (when the agent cannot proceed without user input)
- Logs of issues, self-corrections, and fixes
In the original autoresearch, a single metric (val_bpb) determines whether a version advances. For a coding skill, we need multiple key metrics:
- Test cases passed
- Time
- Token usage
Other metrics act as signals for future improvements.
For simplicity at the design stage, we use a binary score:
- 0 → output code does not match the reference
- 1 → output code matches the reference
Each test case gives 1 point if it passes.
Additionally:
- +1 point if execution time improves vs. previous version
- +1 point if cost improves vs. previous version
Final score = sum of all points
Decision rule:
- If current_score > previous_score -> advance
- Else -> discard and revert
Since we have multiple test cases, correctness dominates the score, which is desirable. Only after maximizing quality do time and cost become deciding factors.
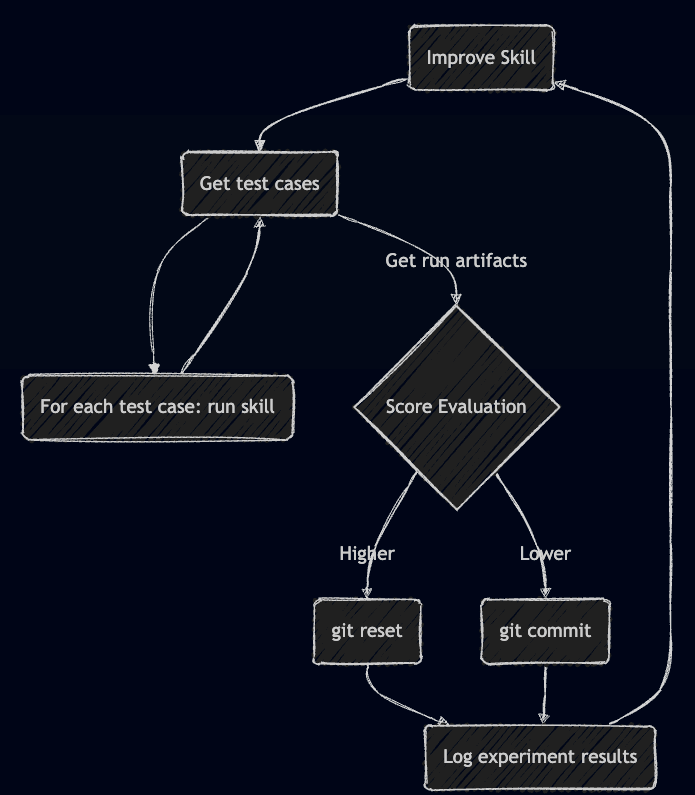
Auto-Improvement Loop
The loop is very similar to the original autoresearch. Each iteration is stateless:
- Take the current SKILL.md, analyze it, and apply a change based on a specific experiment idea
- Boundaries are important: limit the scope of changes
- We want iterative improvement, not full rewrites
- At the same time, changes should not be too small, since evaluation is noisy
- Run all test cases
- Each test case should be executed multiple times to smooth out non-determinism
- Evaluate results
- Aggregate measurements
- Compute the total score
- Compare with the previous best version
- If better -> commit as the new baseline
- If worse -> discard
- Repeat with a new experiment idea
The diagram of the autoimprove loop:
Conclusion
I designed an auto-improvement loop for coding skills based on Andrej Karpathy’s autoresearch approach, originally created for improving LLM training loops.
At a high level, nothing prevents us from applying the same idea to agentic coding. In theory, an agent could autonomously “train” its own coding skills based on specific use cases and a codebase – without human supervision.
That said, there are still many challenges:
- Defining high-quality test cases that cover edge cases
- Setting proper boundaries for skill modifications
- Forcing the agent to explore the full design space (sub-agents, memory strategies, tooling, etc.)
- Deciding when an agent should pull in new tools (CLIs, MCPs) or even build them from scratch
These challenges will likely surface during implementation and early runs. I’ll share more once I have initial results and a working version.

Leave a comment