Introduction
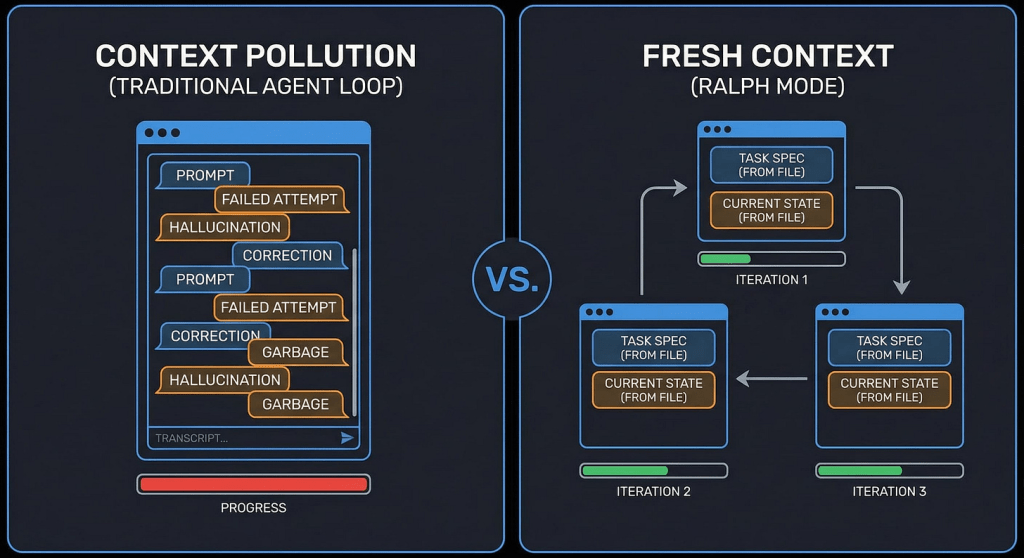
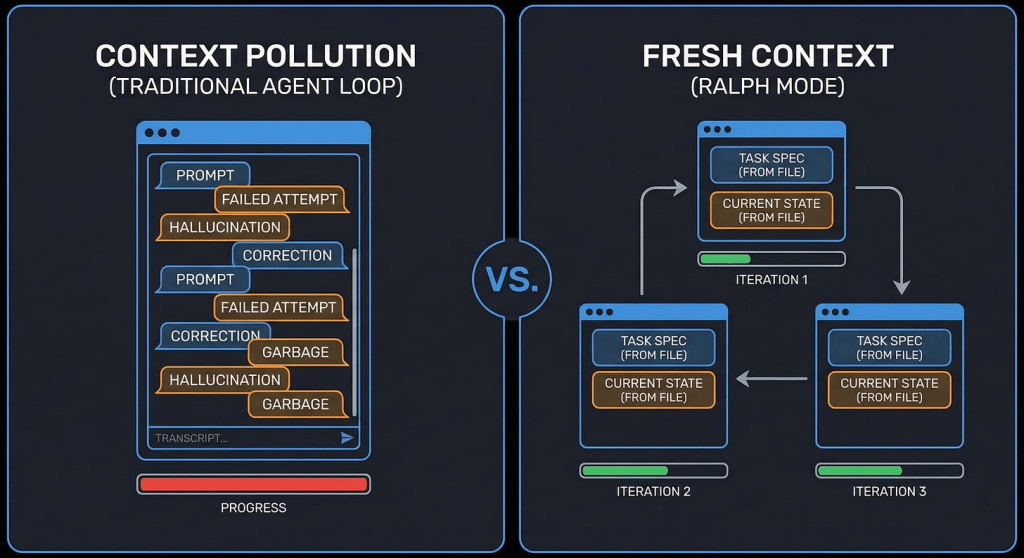
I’ve been testing Ralph loops recently for agentic coding. The idea is simple: spin up new Claude Code sessions for each task to get a fresh context until the agent achieves the goal, and persist the necessary context between sessions via .md files. It’s simple, but it solves many long-known LLM issues like context rot and the generally small size of the context window.
This becomes especially relevant when the agent works with large, complex repositories or infrastructure. In addition, you often want to have a proper research phase to check current best practices and available libraries and their interfaces, which also consumes a lot of context.
Even frontier models like Sonnet and Opus still have relatively small context windows, and that problem won’t disappear anytime soon. But we still need a way to leverage the advantages of agentic coding today.
I didn’t like the approach of spinning up Claude Code sessions programmatically (for example, in bash). In that case, you lose control over the workflow, and you lack options to effectively interrupt the process or change something in the middle of execution.
Solution
I decided to implement my own workflow using the sub-agents and skills features, programming the entire workflow inside a single Claude Code session.
Sub-agents are essentially .md files where you define the role of the agent and its interface: what arguments it takes and what it returns.
I defined agents and their roles for each phase of the workflow. At a high level there are two phases: planning and execution.
The orchestrator and the main workflow are defined in a single SKILL.md file. This file contains zero context about the project itself – only the steps and rules related to the workflow logic.
The planning phase is divided into two main loops:
- the preliminary research loop
- the main planning loop
In this article I want to focus on the preliminary research and interview phase.
This phase is extremely important because it gathers all the context needed to build a solid plan. The broader the context we collect here and the more edge cases we identify, the more likely we are to produce an implementation that:
- meets the original goals and requirements, and
- fits the existing architecture and follows established standards.
The more time we invest here, the less we need to babysit the agent during later phases and during review.
The Preliminary Research Loop
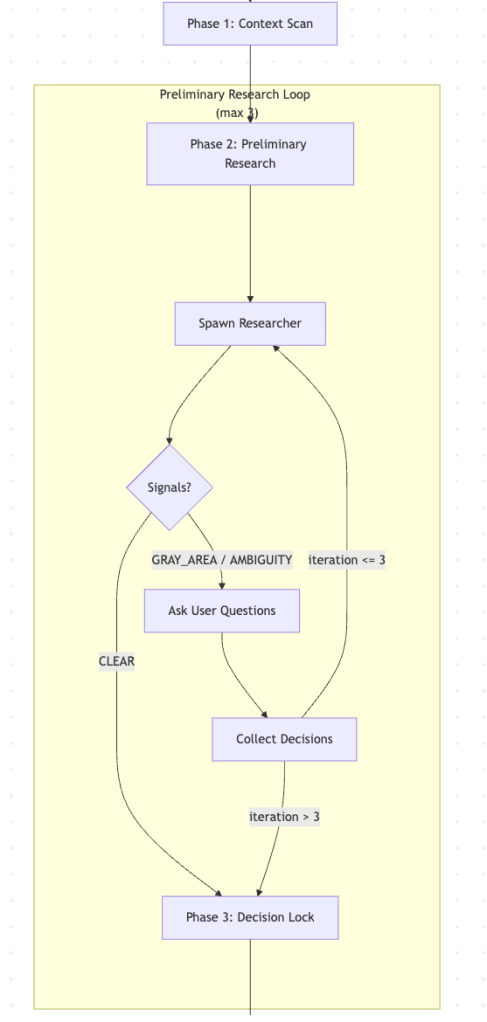
Before entering the main planning loop, the workflow runs a preliminary research loop. The goal of this loop is to identify the scope of the task and resolve ambiguities.
It allows you to start with a very high-level description of the task and then progressively define details and gather context together with Claude Code through an interview loop.
In this phase the agent performs high-level exploration and research without diving into implementation details, just enough to understand the scope and highlight unclear areas.
Questions are presented to the user using the AskUserQuestions Claude Code feature. The interview runs in a loop for up to three iterations, or until no ambiguities remain.
Once the preliminary researcher signals that everything is clear, the orchestrator locks all decisions into the CONTEXT.md file.
How is this phase defined in SKILL.md main orchestrator file:
### Phase 2: Preliminary Research Loop (interactive)Iteratively identify gray areas and collect decisions before locking scope.**Orchestrator state (in-memory, not written to disk):**- `decisions_list`: accumulated user decisions (starts empty)- `scope_in` / `scope_out`: scope boundaries (starts from context scanner suggestion)- `iteration`: counter (starts at 1, max 3)#### Phase 2a: Spawn Preliminary Researcher```Task( prompt="First, read .claude/agents/preliminary-researcher.md for your role.\n\n<context>\nTask: {description}\nTask type: {task_type}\nAffected areas: {affected_areas}\nReferences to load: {reference_list}\nScope:\n IN: {scope_in}\n OUT: {scope_out}\nIteration: {iteration} of 3\n</context>", subagent_type="general-purpose", description="Identify gray areas (iteration {iteration})")```#### Phase 2b: Handle Signals**If CLEAR:****If SCOPE_SUGGESTION (first iteration only):** **If GRAY_AREA / AMBIGUITY:**#### Phase 2c: Collect and Iterate1. Add answers to `decisions_list`2. If "Adjust scope": ask what to change, update `scope_in` / `scope_out`3. Increment `iteration`4. If `iteration <= 3`: go to Phase 2a5. If `iteration > 3`: force-proceed to Phase 3### Phase 3: Decision Lock (orchestrator-direct, interactive)1. Present full decision summary (scope + all decisions + constraints) via `AskUserQuestion` with a single confirmation question2. Create `.workflow/{task-name}/` directory3. Write CONTEXT.md
The preliminary researcher itself is implemented as a sub-agent and its role is defined in /.claude/agents/preliminary-researcher.md:
---name: preliminary-researcherdescription: Identifies gray areas and ambiguities before decisions are locked. Role file for general-purpose subagent. Spawned by workflow plan mode Phase 2.tools: Read, Glob, Grep, Bashmodel: sonnetcolor: cyan---<role>You are the preliminary research subagent for a workflow task. Your job is to identify decision points, ambiguities, and gray areas that need human input before implementation research begins. You do NOT write files or do web research -- you surface what needs deciding.</role><execution_flow><step></step><step></step></execution_flow>
Conclusion
This is how I implemented a preliminary research loop using skills and sub-agents, so you don’t need to detach from the Claude Code session and still retain full control over the workflow.
It allows you to interrupt the process at any step, reconsider decisions, or inject additional context before moving to the planning phase.
At the same time, you still get the advantages of Ralph loops: isolated context windows for context-heavy steps like repository scanning or research, autonomous loops with self-correction, and the ability to inject additional context after each interview iteration.
In the next article, I’ll show what happens in the planning phase and what the deep research phase is, and why separating these phases makes the workflow significantly more reliable.